In SQL theÂ
UNION clause combines the results of two SQL queries into a single table of all matching rows. The two queries must result in the same number of columns and compatible data types in order to unite. Any duplicate records are automatically removed unlessÂUNION ALL is used.
UNION can be useful in data warehouse applications where tables aren’t perfectly normalized.[2] A simple example would be a database having tablesÂsales2005 andÂsales2006 that have identical structures but are separated because of performance considerations. AÂUNION query could combine results from both tables.Note thatÂ
UNION ALLÂdoes not guarantee the order of rows. Rows from the second operand may appear before, after, or mixed with rows from the first operand. In situations where a specific order is desired,ÂORDER BYÂ must be used.Note thatÂ
UNION ALLÂ may be much faster than plainÂUNION.
but in pyspark
This is equivalent to UNION ALL in SQL. To do a SQL-style set union (that does deduplication of elements), use this function followed by a distinct.
Also as standard in SQL, this function resolves columns by position (not by name).
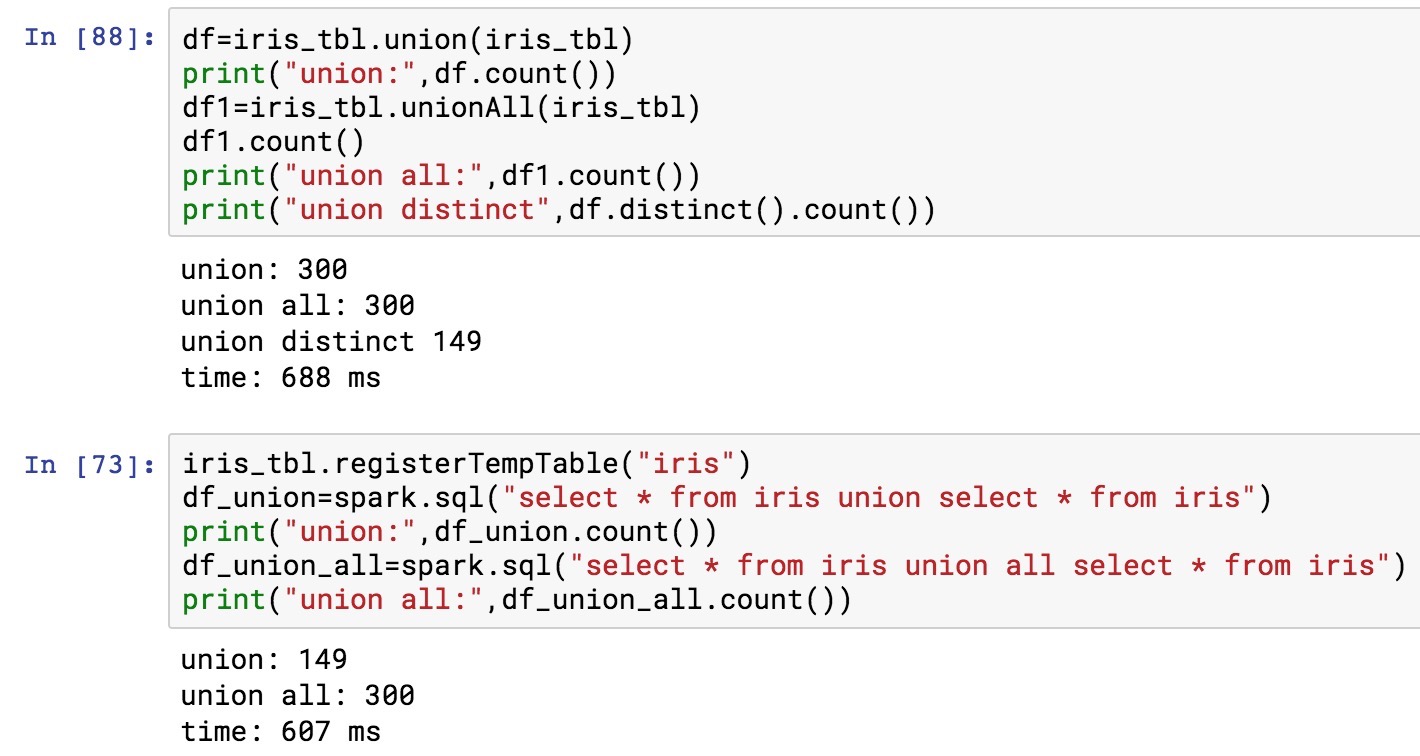
and here is the test code,
from pyspark import SparkConf
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
iris_tbl=spark.read.csv("iris.csv",header=True)
df=iris_tbl.union(iris_tbl)
print("union:",df.count())Â #union: 300
df1=iris_tbl.unionAll(iris_tbl)
print("union all:",df1.count())Â #union all: 300
print("union distinct",df.distinct().count())Â #union distinct 149
iris_tbl.registerTempTable("iris")
df_union=spark.sql("select * from iris union select * from iris")
print("union:",df_union.count())Â #union: 149
df_union_all=spark.sql("select * from iris union all select * from iris")
print("union all:",df_union_all.count())Â #union all: 300