I have done a freelance job that extracted table from PDF with the help of pdftohtml(part of xpdf) and other pdf software that help with this such as sodapdf. First converted PDF to XML, then parsed XML and got csv.
Today I’d like to introduced two packages that can easy convert PDF to CSV or Excel, they are pdfplumber and tabula-py(need JVM).
pdfplumber, Plumb a PDF for detailed information about each text character, rectangle, and line. Plus: Table extraction and visual debugging.
Works best on machine-generated, rather than scanned, PDFs. Built on pdfminer and pdfminer.six.tabula-py is a simple Python wrapper of tabula-java, which can read table of PDF. You can read tables from PDF and convert into pandas’s DataFrame. tabula-py also enables you to convert a PDF file into CSV/TSV/JSON file.
Let install them first,
pip install tabula-py pdfplumber
The test PDF files we will use today are
http://www.cntaiping.com/upload/cms/cntaiping/201809/14174039r1iv.pdf

and
http://202.107.205.11:8612/doc/浙高ä¼è®¤åŠžã€”2018〕3å·å…³äºŽæµ™æ±Ÿçœ2018年第一批拟更å高新技术ä¼ä¸šå…¬ç¤ºåå•.pdf
rename to hangzhou.pdf
from tabula import read_pdfdf = read_pdf("14174039r1iv.pdf")df
the result is bad, let’s try pdfplumber
import pdfplumber
pdf = pdfplumber.open("14174039r1iv.pdf")
# in this example, only extract the first page
p0 = pdf.pages[0]
table = p0.extract_table()
import pandas as pd
df = pd.DataFrame(table[1:], columns=table[0])
df
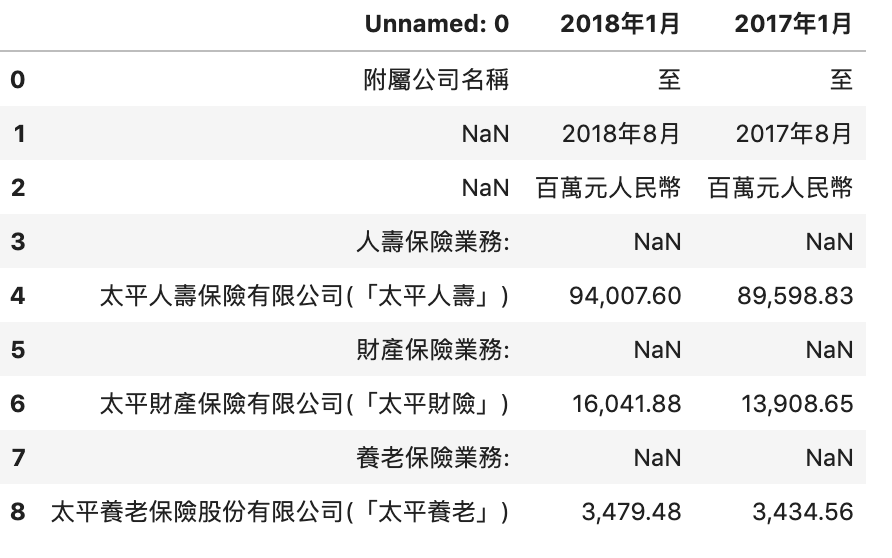
sounds great. Let’s try another PDF
from tabula import read_pdf
df = read_pdf("hangzhou.pdf",pages=3)
df
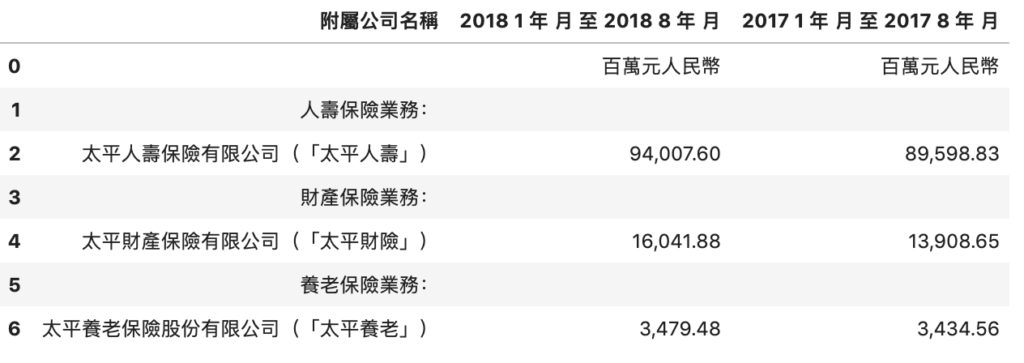
bad result
import pdfplumber
pdf = pdfplumber.open("hangzhou.pdf")
import pandas as pd
for page in pdf.pages:
tables=page.extract_tables() for table in tables:
df=pd.DataFrame(table[1:],columns=table[0])
display(df)
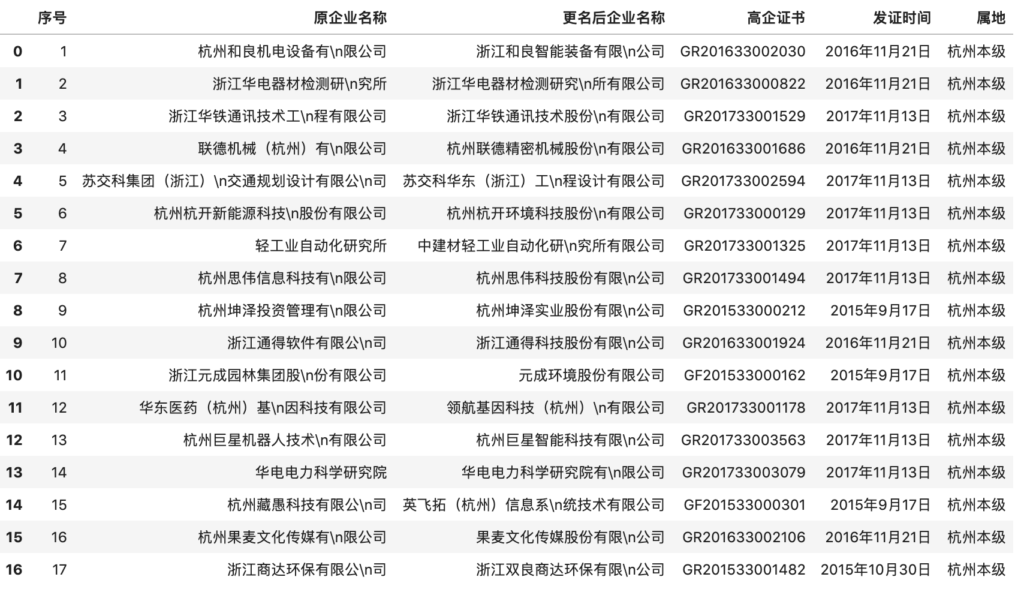
perfect!
from the simple test, pdfplumber is much better than tabula-py and pdfplumber is developed in pure Python.